LoRA: Low-Rank Adaptation of Large Language Models
Authors : Morgane Brossard, Guillaume Pradel
1) Impact and necessity of efficient fine-tuning for LLM models
Imagine that you are a conductor, and that your large language model is an orchestra. All the parameters of the model are elements of the orchestra: Instruments, playing style and music knowledge of every player… Now, let’s say that the musicians have been trained to perform classical music for years, and especially to play in Bethoven’s style. However, you want to introduce some Mozart to the repertoire.
Re-training the model from scratch would be like you deciding to re-teach music from the beginning to the musicians : Long and unnecessary !
Traditional fine-tuning would be to start from the current state of the orchestra, but adapting every aspect of it to the new Mozart style: Re-explaining all the players how to handle violin bow, how to blow in a flute, how to play each note, each rhythm, all in the style of Mozart. But while the rhythm might be relevant to adapt to Mozart style, how to blow in the flute isn’t : Still not effective enough !
Now, what if you simply provided the musicians with notes on certain parts of their partition necessitating instructions specific to Mozart style ? They only need to adapt a few style elements to switch from Bethoven’s style to Mozart !
This is what LoRA (Low-Rank Adaptation of Large Language Models) is about: instead of re-training the entire model, it freezes the main weights and injects small, trainable matrices to adapt the model efficiently.
2) The Challenge of Fine-Tuning Large Neural Networks
How Does Fine-Tuning Usually Work?
Fine-tuning is a common method for adapting pre-trained neural networks to specific tasks. It involves adjusting the model’s weights to minimize a task-specific loss function.
$$\Theta^* = \arg\min_{\Theta} \sum_{(x_i, y_i) \in D} L(f_{\Theta}(x_i), y_i)$$
However, for large models like GPT-3 (175B parameters), full fine-tuning has major drawbacks:
- Storage: Each fine-tuned model requires as much space as the original model.
- Memory: The training process demands enormous GPU memory, making fine-tuning inaccessible to many users.
- Inference Latency: Some methods introduce additional processing layers, slowing down real-time applications.
3) The LoRA Approach: A More Efficient Solution
LoRA is a method created by Hu. et al (team of researchers from Microsoft) in 2021 in the paper LoRA: Low Rank Adaptation of Large Language Models.
LoRA addresses the fine-tuning challenge with a simple but powerful idea: don’t modify the original model weights, but instead inject trainable low-rank matrices into each Transformer layer, making fine-tuning both memory-efficient and computationally affordableby tuning only those matrices’ parameters.
A) How LoRA Works: The Key Innovation
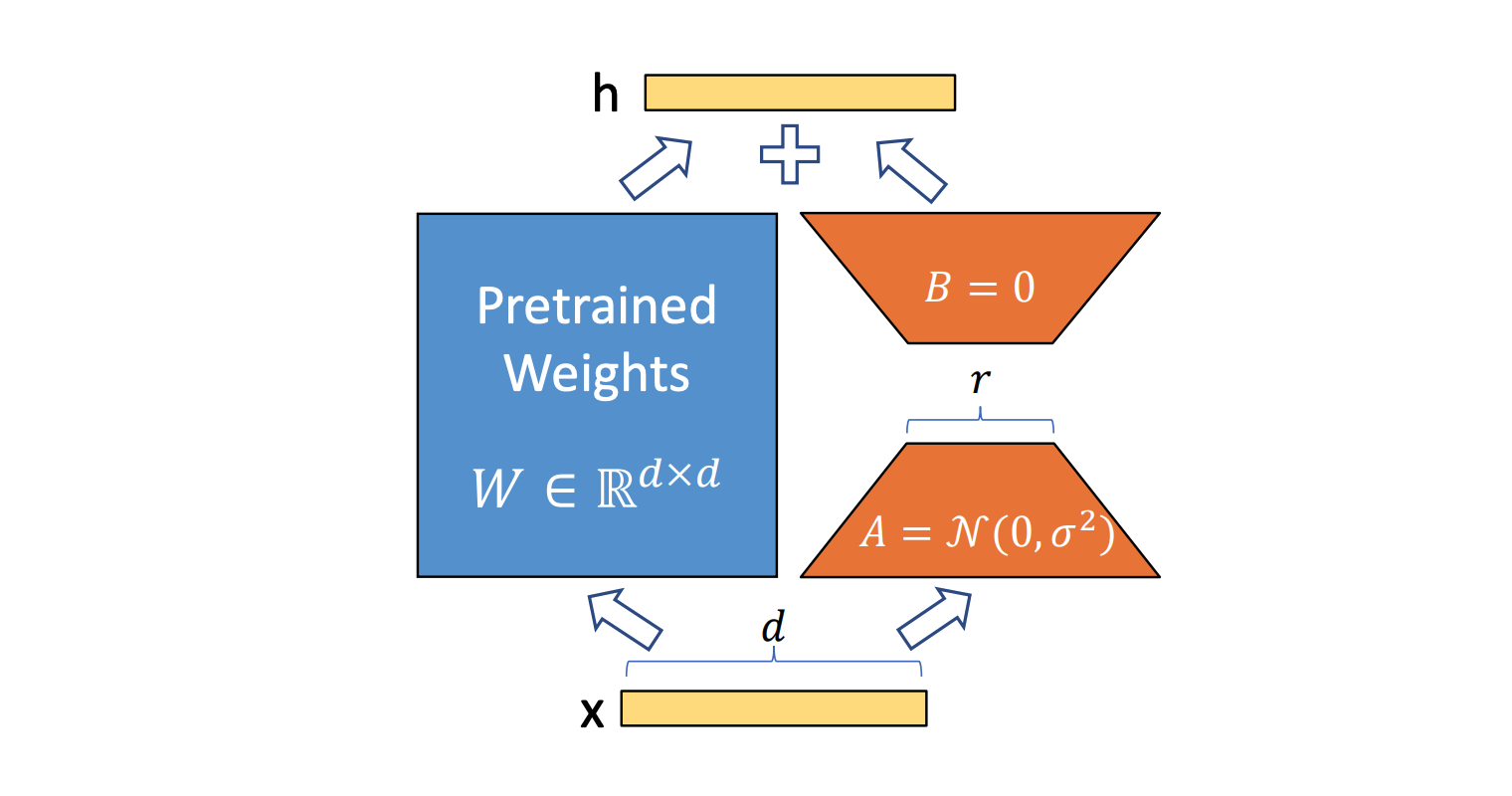
Instead of modifying the full weight matrix $W$ during fine-tuning, LoRA replaces the weight update with a low-rank decomposition :
$$\Delta W = B A$$
where:
- A is a small trainable matrix of size r × d
- B is another small trainable matrix of size d × r
- r (rank) is much smaller than d, making the update computationally cheap.
This means we freeze the pre-trained model’s weights and only train the new low-rank matrices. The total number of trainable parameters is drastically reduced compared to a full fine-tuning.
Mathematical Formulation
For a given input $x$, a neural network layer applies a weight matrix $W$ :
$$h = Wx$$
During fine-tuning, the full update would be:
$$W’ = W + \Delta W$$
In LoRA, we approximate delta W using two low-rank matrices:
$$W’ x = W x + \frac{\alpha}{r} B A x$$
where alpha is a scaling factor that controls the magnitude of the adaptation.
These equations can also be shown in this way :
B) LoRA Applied to Transformer Layers
Transformers are the backbone of modern NLP models, enabling them to process and generate human-like text. At the heart of a Transformer is the self-attention mechanism, which allows the model to weigh different words in a sequence based on their relevance to each other. Each Transformer layer consists of multiple self-attention heads and feedforward layers, making it highly expressive but also computationally expensive. Self-attention is computed using three key matrices —query (Q), key (K), and value (V)— which determine how tokens interact within a given input sequence. Fine-tuning these large matrices for every new task can be impractical, which is where LoRA provides an efficient alternative.
In Transformer-based architectures, LoRA is typically applied within self-attention layers. In a Transformer, the query (Q), key (K), and value (V) matrices are learned using standard weight matrices $W_q$, $W_k$, $W_v$:
$$Q = W_q X, \quad K = W_k X, \quad V = W_v X$$
Instead of updating directly, LoRA replaces the weight updates with its low-rank approximation:
$$W_q’ = W_q + B_q A_q, \quad W_v’ = W_v + B_v A_v$$
Applying LoRA only to the query and value projections has been found to be sufficient for effective adaptation, reducing computation while maintaining performance.
In our orchestra analogy, the low-rank matrices are the little notes given to the players to adapt their playing to Mozart’s style !!
C) Benefits of LoRA
✅ Massive Reduction in Trainable Parameters: LoRA can reduce the trainable parameters by up to 10,000× compared to full fine-tuning.
✅ Lower GPU Memory Usage: Requires only 1/3 the memory compared to fine-tuning with Adam.
✅ No Additional Inference Latency: LoRA updates can be merged back into the model, eliminating extra computation at inference time.
✅ Faster Fine-Tuning: LoRA achieves 25% higher training throughput on large models
4) Implementing LoRA in Practice
Loading the model and first test
The first step before using LoRA is to download a model. Here, we download LLama-3 with 4-bit quantization, which reduces memory usage and speeds up inference. We also load a tokenizer that splits the input text.
MODEL_NAME = "unsloth/Llama-3.2-1B"
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type='nf4',
bnb_4bit_compute_dtype=torch.bfloat16,
)
model = AutoModelForCausalLM.from_pretrained(
MODEL_NAME,
device_map="auto",
trust_remote_code=True,
quantization_config=bnb_config,
)
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
tokenizer.pad_token = tokenizer.eos_token
We can the define the prompt to pass to the llm : ‘What equipment do I need for rock climbing ?’
prompt = '<human>: What equipment do I need for rock climbing? \n <assistant>: '
generation_config = model.generation_config
generation_config.max_new_tokens = 200
generation_config.temperature = 1000
generation_config.top_p = 0.7
generation_config.num_return_sequences = 1
generation_config.pad_token_id = tokenizer.eos_token_id
generation_config.eos_token_id = tokenizer.eos_token_id
device = "cuda:0"
encoding = tokenizer(prompt, return_tensors="pt").to(device)
with torch.inference_mode():
outputs = model.generate(
input_ids=encoding.input_ids,
attention_mask=encoding.attention_mask,
generation_config=generation_config,
)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
The LLM’s response before fine-tuning with LoRA is:
1. A harness with a carabiner. 2. A rope. 3. A helmet. 4. A harness with a carabiner.
We can already notice some redundancy due to the low temperature (the temperature will increase or decrease the level of confidence of the model). Moreover the response is not well-structured—it consists only of bullet points.
Fine-tuning with LoRA
Now, we will load a question-and-answer dataset to fine-tune with LoRA. We will use the Hugging Face library, which is perfect for this.
data = load_dataset("HuggingFaceH4/helpful-instructions")
pd.DataFrame(data["train"])
def generate_prompt(data_point):
instruction = data_point['instruction']
demonstration = data_point['demonstration']
return "<human>: " + instruction + " \n <assistant>: " + demonstration
def generate_and_tokenize_prompt(data_point):
full_prompt = generate_prompt(data_point)
tokenized_full_prompt = tokenizer(full_prompt, padding=True, truncation=True)
return tokenized_full_prompt
data = data["train"].shuffle(seed=42).map(generate_and_tokenize_prompt)
OUTPUT_DIR = "experiments"
training_args = transformers.TrainingArguments(
per_device_train_batch_size=1,
gradient_accumulation_steps=4,
num_train_epochs=1,
learning_rate=2e-4,
fp16=True,
save_total_limit=3,
logging_steps=1,
output_dir=OUTPUT_DIR,
max_steps=200,
optim="paged_adamw_8bit",
lr_scheduler_type="cosine",
warmup_ratio=0.05,
report_to="tensorboard",
)
trainer = transformers.Trainer(
model=model,
train_dataset=data,
args=training_args,
data_collator=transformers.DataCollatorForLanguageModeling(tokenizer, mlm=False),
)
model.config.use_cache = False
trainer.train()
Training is also very easy with Hugging Face. You just need to define the training arguments using .TrainingArguments and set up the trainer with .Trainer. This showcases how simple it is to use LoRA for fine-tuning !
device = "cuda:0"
encoding = tokenizer(prompt, return_tensors="pt").to(device)
with torch.inference_mode():
outputs = model.generate(
input_ids=encoding.input_ids,
attention_mask=encoding.attention_mask,
generation_config=generation_config,
)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
We then get the response to the same question after fine-tuning:
Rock climbing is a very physically demanding sport. You will need a good pair of climbing shoes, a good pair of climbing gloves, a good pair of climbing socks, a good pair of climbing harness.
We still notice a lot of redundancy with “a good pair,” which is due to the low temperature. However, the response is much better structured and is no longer just bullet points. The LLM has become almost “human”! And this only required about ten minutes of training on a mid-range GPU.
5) Experimental Results: LoRA vs. Other Methods
The authors tested LoRA on tasks such as GLUE (NLP benchmarks), WikiSQL (Text-to-SQL), and SAMSum (Summarization). The results showed:
- Performance on par or better than full fine-tuning.
- GPU memory usage reduced by 3×.
- Inference speed unchanged (unlike adapters which introduce latency).
| Model | Fine-Tuning Type | Trainable Params | Memory Usage | Inference Latency |
|---|---|---|---|---|
| GPT-3 (175B) | Full Fine-Tuning | 175B | 1.2TB | Low |
| GPT-3 (175B) | LoRA (r=4) | 4.7M | 350GB | Low |
| GPT-3 (175B) | Adapter Layers | 40M | 450GB | High |
6) LoRA popularity and applications
LoRA has become a major breakthrough in the world of LLMs and has been recognized by key AI players like Meta, which even published a guide on how to fine-tune their model, LLaMA, using LoRA (https://www.llama.com/docs/how-to-guides/fine-tuning/). This method has become one of the most widely used for fine-tuning due to its ability to be highly resource-efficient. Its popularity is also driven by its ease of access—fine-tuning a model with LoRA is straightforward thanks to libraries like Hugging Face, which already provide built-in support for it.
LoRA is now used in complex tasks and has been widely adopted by researchers. The original research paper has even been cited over 12,000 times ! One notable example is LoRA-Whisper: Parameter-Efficient and Extensible Multilingual ASR, where OpenAI’s Whisper (a speech recognition model) was fine-tuned with LoRA to improve its performance for specific languages and accents.
Another example is Phi-2 LoRA fine-tuning, where Microsoft’s Phi-2 model, a small yet highly capable language model, was adapted using LoRA to perform well on domain-specific tasks such as Text-to-SQL while maintaining very low computational costs.
Thus, since the article was published in 2021, LoRA has established itself as an essential method for fine-tuning and is now widely adopted in both research and industry for its efficiency in adapting large models with efficient resource usage.
7) Conclusion
LoRA revolutionizes fine-tuning by reducing storage, compute, and inference overhead, making LLMs accessible to more researchers and developers. By implementing LoRA, we can adapt powerful models efficiently, unlocking their potential for a wide range of applications without the heavy costs of full fine-tuning. Future research may combine LoRA with other parameter-efficient methods like prefix tuning or explore rank-selection techniques to optimize adaptation further.
Test Your Understanding !
Take this quiz to check your knowledge:
Why is full fine-tuning inefficient for large models?
- A. It updates too few parameters
- B. It requires excessive memory and storage
- C. It slows down inference
What does LoRA modify in the Transformer architecture?
- A. It adds low-rank transformer blocks
- B. It injects low-rank matrices into self-attention layers
- C. It compresses the transformer weights before training
Why does LoRA have no additional inference latency?
- A. Because the low-rank updates are merged into the original model before inference
- B. Because it skips backpropagation
- C. Because it uses an optimized inference engine
Are you ready to implement LoRA on your next NLP project? Check out this HuggingFace tutorial to get you started ! https://huggingface.co/docs/peft/main/conceptual_guides/lora
Answer to the quizz : B, B, A
References
Hu, Edward J., Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-Rank Adaptation of Large Language Models. (2021)
Song, Zheshu, Jianheng Zhuo, Yifan Yang, Ziyang Ma, Shixiong Zhang, and Xie Chen. LoRA-Whisper: Parameter-Efficient and Extensible Multilingual ASR.(2024)
Meta website : https://www.llama.com/docs/how-to-guides/fine-tuning/
Solulab website : https://www.solulab.com/fine-tuning-a-model-for-a-specific-task/